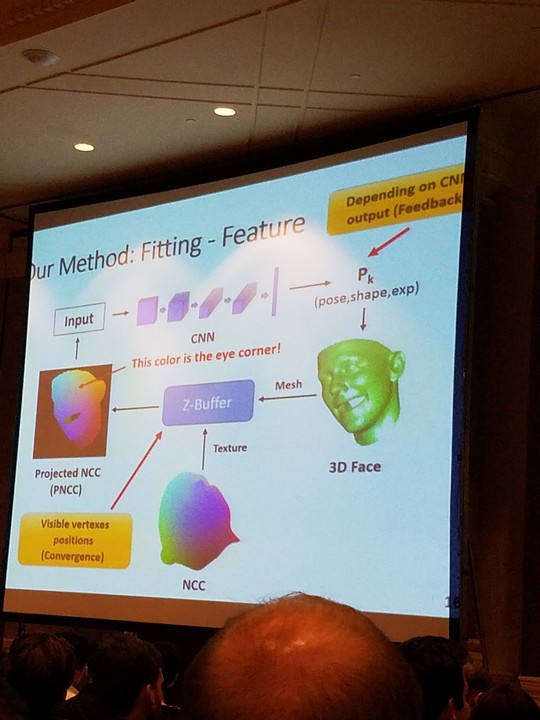
On Tuesday, the major show is the Face session! However, we have to say that Face related research is not like the main thing in CVPR. As the session name indicates: “Computational Photography and Faces”. Sure, we have a lot of poster about face modeling and expression detection, but the limited oral session tells the trend now. No worry, however, in SIGGRAPH, Face session is always packed up with people!
So in the afternoon oral session, we have 5 oral presentations, which definitely shine the state-of-the-art work in this region. I am so much loving this section due to the fact that this is what I belong to, and of course, our lab has contributed to one of the paper!
13. Recurrent Face Aging: a cool data set in 2D which contains a lot of faces covering large aging space is crated and used to predict human aged face.
14. Face2Face: Real-Time Face Capture and Reenactment of RGB Videos: What I can say, the jaw-dropping demo video since last SIGGRAPH Aisa. This time they updated the model to work with only 2D rgb image. The presentation is cool because it ends with a live demo with Putin as the target agent! So the Basel Morph Model is used to do identity morphing, which need the user to show a frontal face, rotate left then right to create subject dependent 3D face model. The initialization procedure takes about 30 seconds. Then we obtain a fully controllable avatar. The texture albedo is also learned. Based on my demo test, the system is pretty nice and smooth, however, don’t expect it can handle directional light, might just be like the global light source. Without tongue model, it is still can accurately modeling the lip movement so normal speaking should be OK. There are more interesting story behind this. To me, it is such a nice experience to meet the authors here at CVPR!
15. Self-Adaptive matrix Completion for Heart Rate Estimation From Face Videos Under Realistic Conditions: A stable face region is located in the general face image and the model can used to detect the heart rate from the image space. It is just so glad to see the demo and illustration video/image are actually from our database!
16. Visually Indicated Sounds: MIT always has the balls to do cool stuff. The authors notice that human beings can indicate the sound of the materials pretty well even only with the image. So they spend a lot of time to use drum stick to hit “A LOT” object and recording with video camera. Then they train the deep learning model so that the machine can pick up the motion of drum stick hit certain “objects” and simulate the corresponding audio.
We know that in movies, sometimes the audio composers can not get the real some of the scene due to different reasons and need to create the audio effect with other stuff. This CVPR paper is like a auto way to do this.
17. Image Style Transfer Using Convolutional Neural Network: Transfer Van Gogh’s painting style to your image automatically? This is the instruction for you.
Here are some photos again, to cover the topics on the second day.